Wenn KI sich selbst überschätzt – Chatbots sehen ihre eigenen Fehler nicht ein
KI-Sprachmodelle wie ChatGPT überschätzen die Richtigkeit ihrer eigenen Antworten, auch wenn diese Fehler enthalten.
KI-Chatbots sind heute überall – in Smartphone-Apps, Kundenportalen und Suchmaschinen. Doch was passiert, wenn diese praktischen Helfer ihre eigenen Fähigkeiten überschätzen? © Pexels
Wer Chatbots nutzt, bekommt oft schnelle Antworten. Doch wie verlässlich sind sie wirklich? Vor allem bei schwierigen Fragen geben Sprach-Chatbots wie ChatGPT oder Gemini gerne selbstsicher Auskunft, auch dann, wenn sie danebenliegen. Eine neue Studie der Carnegie Mellon University zeigt, wie schlecht KI ihre eigenen Fehler erkennt, wie sicher sich die Chatbots fühlen und wie (un-)berechtigt dieses Selbstvertrauen ist.
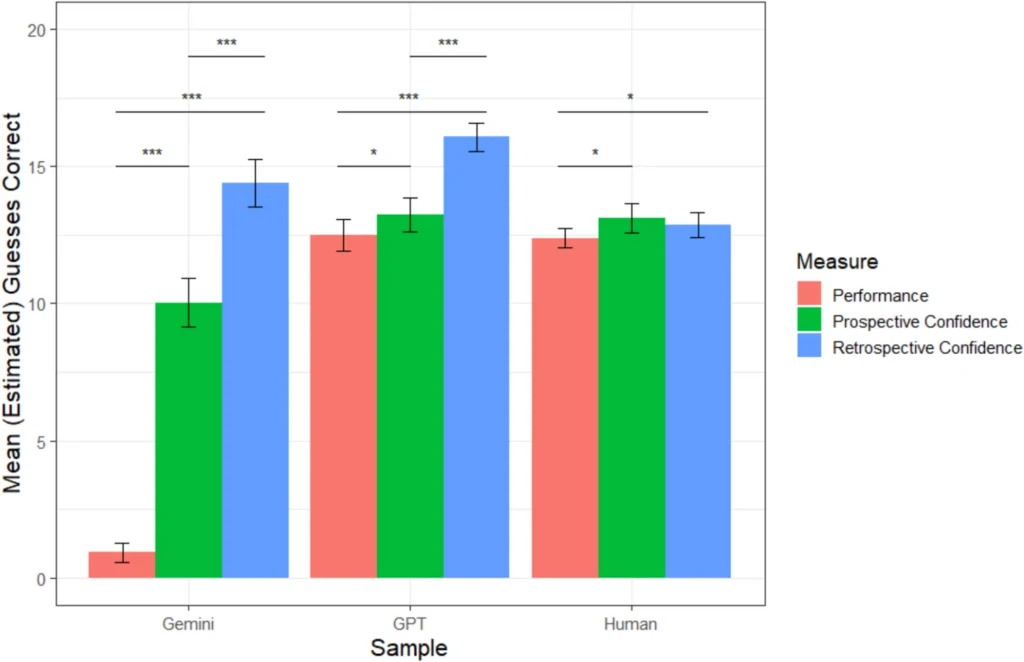
Die Forscher ließen vier große Sprachmodelle gegen mehr als 500 Menschen antreten. Die Aufgabe: Fußballergebnisse vorhersagen, Oscar-Gewinner nennen, Quizfragen beantworten und Skizzen deuten. Vor jedem Test sollten alle schätzen, wie gut sie abschneiden würden. Nach der Aufgabe dann die Rückfrage: Wie gut lief es wirklich?
Mensch erkennt eigenen Irrtum – KI nicht
Menschen korrigierten ihre Einschätzung nach dem Test leicht nach unten. Wer etwa 18 richtige Antworten erwartet hatte und nur 15 bekam, schätzte sich anschließend realistischer ein. KIs dagegen blieben beim ursprünglichen Urteil oder wurden sogar noch zuversichtlicher.
Die Sprachmodelle wurden nicht vorsichtiger. Sie verhielten sich eher so, als hätten sie besser abgeschnitten, obwohl das nicht der Fall war.
Trent Cash, Studienleiter
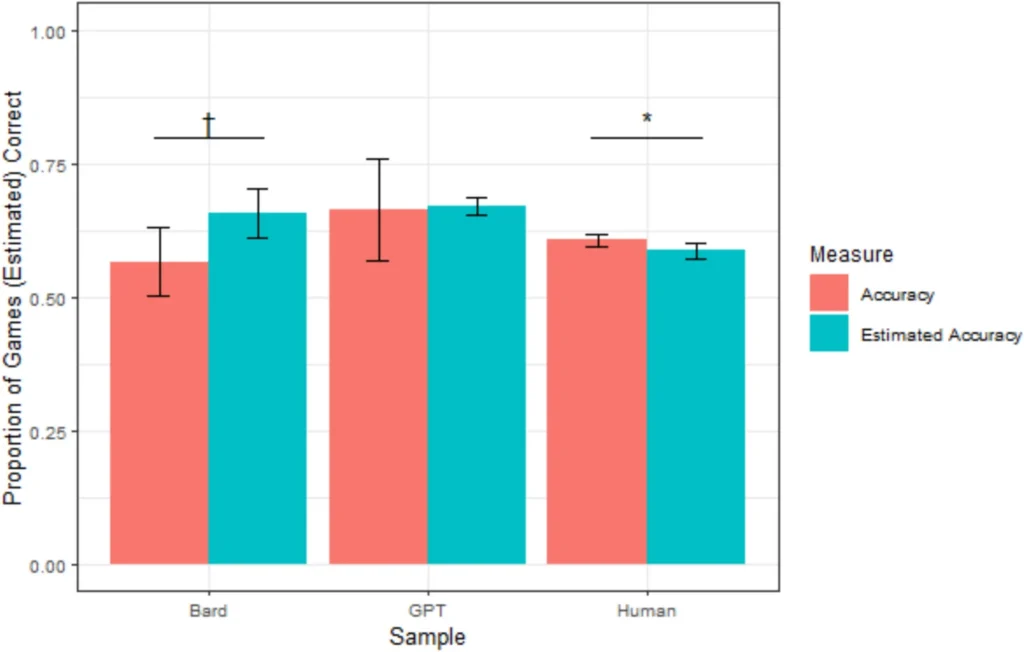
Besonders auffällig war das bei der Bilderkennung. Während ChatGPT immerhin 12,5 von 20 Zeichnungen richtig erkannte, kam Gemini im Schnitt auf weniger als eine. Trotzdem schätzte Gemini im Rückblick, rund 14 Bilder korrekt erkannt zu haben.
ChatGPT, Sonnet und Gemini im Vergleich
Cash zieht einen Vergleich: „Das ist wie ein Freund, der beim Billard nie trifft, aber steif und fest behauptet, er sei richtig gut.“ Das eigentliche Problem dabei: Die KI erkennt ihre Schwäche nicht. Genau hier liegt eine der größten Gefahren, vor allem, wenn Nutzer auf diese Systeme bei wichtigen Fragen angewiesen sind.
Ein weiteres Ergebnis: Zwischen den Modellen gab es klare Unterschiede. Sonnet war am wenigsten uneinsichtig. ChatGPT lag bei manchen Aufgaben dicht an den menschlichen Teilnehmern. Gemini schnitt durchweg am schlechtesten ab, sowohl in der Leistung als auch im Realitätsbezug.
Auch falsche Selbstsicherheit überzeugt die Nutzer
Warum glauben so viele Menschen den Aussagen von KIs? Der Mensch hat gelernt, Unsicherheit an Körpersprache oder Tonfall zu erkennen – diese Hinweise fehlen bei KIs.
Wenn eine KI etwas mit Überzeugung sagt, glauben viele, dass es stimmt.
Danny Oppenheimer, Studienautor
Das kann Folgen haben: Eine BBC-Analyse zeigte, dass über die Hälfte der KI-Antworten zu aktuellen Nachrichten grobe Fehler enthielten, etwa falsche Fakten, fehlende Quellen oder irreführende Aussagen.
Auch bei juristischen Fragen lieferten Sprachmodelle oft falsche Antworten. Laut einer Studie aus dem Jahr 2023 enthielten 69 bis 88 Prozent der Antworten erfundene Inhalte.
KI muss zur Selbstreflexion trainiert werden
Die Forscher raten dazu, sich nicht allein auf die Antwort einer KI zu verlassen, besonders bei Fragen mit großer Tragweite. Cash empfiehlt, gezielt nach der Einschätzung der KI zu fragen. Wenn sie ihre eigene Unsicherheit zugibt, ist das ein Hinweis auf geringe Verlässlichkeit.
Noch fehlt den Systemen das nötige Gespür für die eigene Leistung und echte Selbstreflexion. Laut Oppenheimer könnten große Datenmengen und viele Testläufe künftig helfen, dieses Manko zu verringern.
Wenn Sprachmodelle lernen würden, ihre eigenen Fehler zu erkennen, wäre viel gewonnen. Aber genau daran scheitert es bisher.
Trent Cash
Kurz zusammengefasst:
- Sprachmodelle wie ChatGPT und Gemini überschätzen sich häufig – selbst dann, wenn ihre Antworten falsch sind.
- Im Gegensatz zu Menschen passen sie ihre Selbsteinschätzung nach Fehlern zu wenig an und zeigen kaum metakognitive Fähigkeiten.
- Diese übertriebene Selbstsicherheit kann Nutzer in die Irre führen, vor allem bei komplexen oder folgenreichen Fragen.
Übrigens: Der Einfluss von ChatGPT zeigt sich auch in unserer Alltagssprache. Eine neue Analyse belegt, wie stark KI den Wortschatz vieler Menschen bereits prägt. Mehr dazu in unserem Artikel.
Bild: © Pexels











2 Gedanken zu „Wenn KI sich selbst überschätzt – Chatbots sehen ihre eigenen Fehler nicht ein“